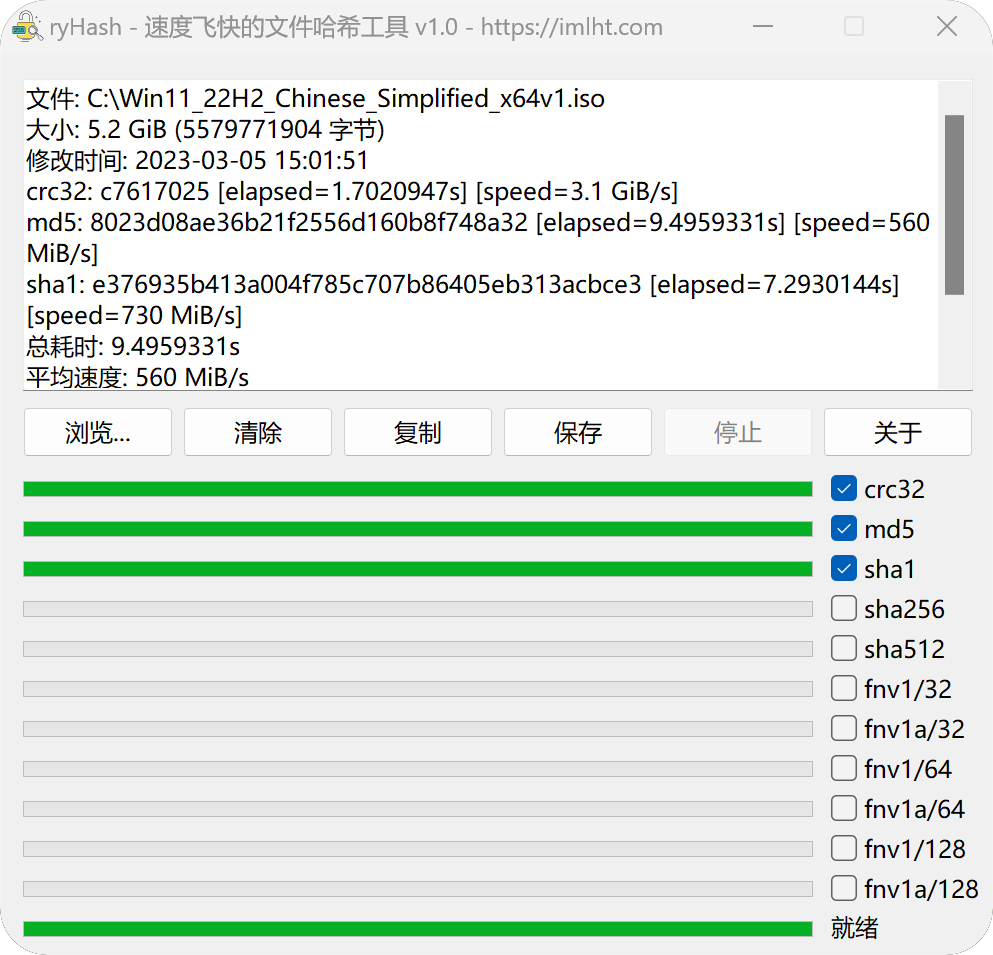
五一长假,大家都出去玩了。
独自一人在家闲着没事,心血来潮开撸日志查询系统——Gobana(Gobana = Golang + Kibana)!
是的,它使用 Go 语言开发,我希望可以替代日常使用的 Kibana!
Kibana 其实有挺多缺点,简单的日志查询写语句还是比较简单的,但是对于更多关键词,你需要写括号 (、),或者是逻辑运算符 AND, OR!
仔细想想,它其实并不是必须的:
因为,大部分情况下,我们查日志
都是需要命中某些关键词,或者是排除某些关键词。
所以如果提供输入框,约定好查询的格式,我想就可以节省很多时间了!
欢迎参观,我会抽空开发,项目地址:https://github.com/Lofanmi/gobana/
6 月啦,补充一张图片上来~

规划中的功能:
- 支持 Elasticsearch
- 支持阿里云 SLS 查询
- 支持 Kibana-Proxy 工作模式(如果运维同学没有 Elasticsearch 地址,只提供 Kibana 的权限的话)【首创!!!】
- 支持图表展示
- 按照业务归类常用的查询语句
- 内嵌 Lua 解析引擎,理论上支持任意类型的日志!【首创!!!】
预计 6 月份发初版,敬请期待吧。